Imagine managing a growing logistics company with a fleet of 100 drivers, each handling an average of 10 orders per customer. PostgreSQL, your chosen database, handles daily operations smoothly. However, complex analytics involving joins and aggregations across multiple tables become sluggish as your data volume grows.
The Problem:
- PostgreSQL excels at basic transactions, but struggles with complex logistics analytics requiring:
- Joining real-time GPS data, order details, and customer addresses for route optimization.
- Joining order timestamps, delivery statuses, and customer information to assess delivery efficiency.
- Extensive joins and aggregations slow down PostgreSQL due to table scans and lookups.
The Scaling Challenge:
- As you add drivers and customers, data volume and complexity explode in PostgreSQL.
- Complex analytical tasks like route optimization and delivery efficiency require even more joins and aggregations.
Why Clickhouse?
In such a case the ideal scenario for a company would be to set up a real-time replication pipeline from their transactional database (Postgres in this case), to something like a ClickHouse - which is optimised for analytical queries on a large dataset.
In this scenario, using ClickHouse alongside PostgreSQL can be a game-changer for the logistics company's data analytics needs. Here's why:
- Columnar Data Storage: ClickHouse stores data in a way that's perfect for analytics. It organises data by columns, which makes it super fast to search and retrieve just the bits of data needed for a query. On the other hand, PostgreSQL stores data row by row, which can slow things down, especially when dealing with large datasets - as it requires an entire table scan for performing extensive joins.
- Materialized Views: ClickHouse offers built-in support for materialized views, which are precomputed query results stored as tables. These materialized views can significantly improve query performance by eliminating the need to repeatedly perform complex calculations or joins on large datasets. This feature streamlines analytical queries, leading to faster insights and more efficient data analysis workflows.
- Scalability: ClickHouse is designed to handle massive datasets and can scale horizontally by distributing data across multiple nodes. This scalability ensures that as the company grows and its data volumes increase, ClickHouse can seamlessly accommodate the expanding workload without sacrificing performance.
Performance Comparisons
Let’s take a look at some analytical queries that one would see in a real world scenario like mentioned above, and see how each of these databases perform.
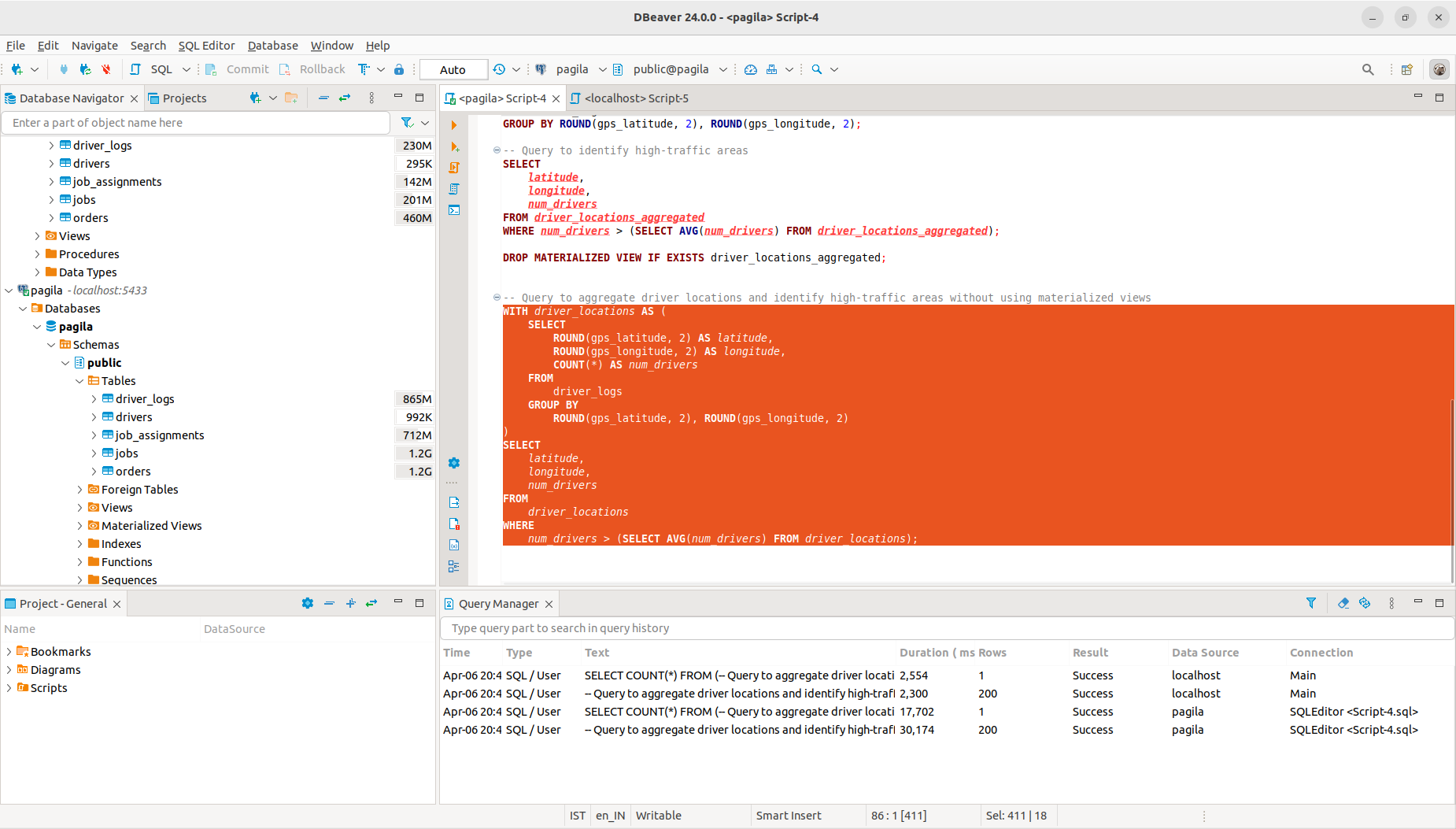
As explained in the problem statement, we have 5 tables namely - orders, jobs, drivers, driver_logs, job_assignments. Now, for the performance comparison between the query execution times in clickhouse and postgres databases, we take an example of an SQL query which can be highly useful in the real time analytics of the scenarios that a logistics company would face.
The SQL query selects rounded off latitude and longitude coordinates from the intermediate table "driver_locations" alongside the count of drivers at each location. It then filters the results to include only records where the number of drivers exceeds the average across all locations.
Essentially, this query identifies high-traffic areas by pinpointing GPS coordinates with an above-average concentration of drivers, aiding in the analysis and decision-making processes for optimizing driver deployment and route planning in logistics operations.
The single-read query would look something like:
-- Query to aggregate driver locations and identify high-traffic areas without using materialized views
WITH driver_locations AS (
SELECT
ROUND(gps_latitude, 2) AS latitude,
ROUND(gps_longitude, 2) AS longitude,
COUNT(*) AS num_drivers
FROM
driver_logs
GROUP BY
ROUND(gps_latitude, 2), ROUND(gps_longitude, 2)
)
SELECT
latitude,
longitude,
num_drivers
FROM
driver_locations
WHERE
num_drivers > (SELECT AVG(num_drivers) FROM driver_locations);
Querying Postgres VS Querying Clickhouse (Non materialised)
After conducting a performance comparison between ClickHouse and PostgreSQL databases on a dataset containing approximately 10 million records using the provided SQL query, the outcomes are as follows:
In the case of the ClickHouse database, the query execution time is impressively swift, clocking in at 2300 milliseconds (ms). Conversely, for the PostgreSQL database, the query execution time is noticeably longer, measuring 30174 ms (>30 seconds). This stark difference illustrates that ClickHouse outperforms PostgreSQL by nearly fifteen times in terms of query execution speed.
These findings underscore the significant advantage that ClickHouse offers in handling analytical queries efficiently, particularly in scenarios where real-time insights are crucial for logistics operations.
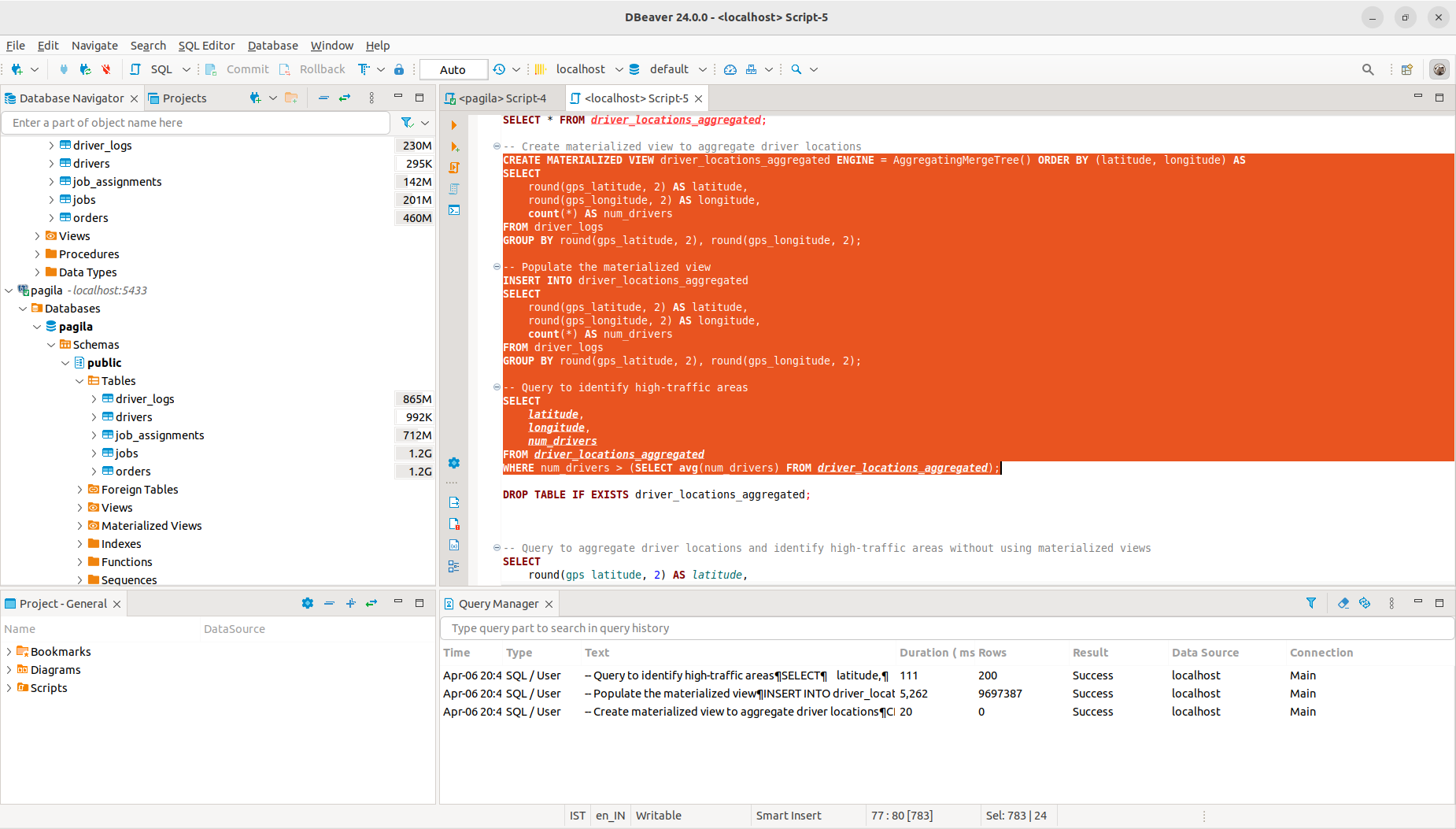
Querying Postgres VS Querying Clickhouse (Materialised)
Similarly, we can also try having a materialised view for the situation, and then run a single read query on that view. So the query would look something like:
--Create materialised view to aggregate driver locations
CREATE MATERIALIZED VIEW driver_locations_aggregated ENGINE = AggregatingMergeTree() ORDER BY (latitude, longitude) AS
SELECT
round(gps_latitude, 2) AS latitude,
round(gps_longitude, 2) AS longitude,
count(*) AS num_drivers
FROM driver_logs
GROUP BY round(gps_latitude, 2), round(gps_longitude, 2);
-- Populate the materialised view
INSERT INTO driver_locations_aggregated
SELECT
round(gps_latitude, 2) AS latitude,
round(gps_longitude, 2) AS longitude,
count(*) AS num_drivers
FROM driver_logs
GROUP BY round(gps_latitude, 2), round(gps_longitude, 2);
-- Query to identify high-traffic areas
SELECT
latitude,
longitude,
num_drivers
FROM driver_locations_aggregated
WHERE num_drivers > (SELECT avg(num_drivers) FROM driver_locations_aggregated);
In this case, we can observe that querying a materialized view on Clickhouse takes 111ms which is more than 270 times faster than querying a Postgres (which took us ~30 seconds).
These findings reinforce ClickHouse's superiority in handling analytical tasks, offering quicker insights and enabling more responsive decision-making in logistics operations.
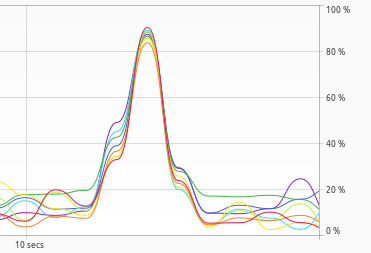
CPU Utilisation
ClickHouse demonstrates superior efficiency in handling queries compared to Postgres, evident in CPU utilization metrics. ClickHouse (materialized) evenly distributes CPU usage across all cores in a multi-core system, maintaining a maximum of 80% utilization (on a 8GB RAM machine). In contrast, Postgres shows uneven distribution, with some cores reaching 100% utilization while others hover around 20%.
Clickhouse
Postgres

Conclusion
Comparing the performance of ClickHouse and PostgreSQL databases shows that ClickHouse is better at handling complex queries efficiently.
By using both ClickHouse and PostgreSQL together, logistics companies can have a complete solution that combines transactional reliability with strong analytical capabilities. Connecting PostgreSQL to ClickHouse in real-time allows for smooth integration of transactional and analytical data, making the most of each database's strengths for better overall performance.
Moreover, ClickHouse's use of materialized views simplifies analytical tasks, making it faster to gain insights and make decisions in real-time analytics situations. This hybrid approach, using PostgreSQL for transactions and ClickHouse with materialized views for real-time analytics, gives logistics companies an edge in the market.
Dozer stands out as a great tool for this setup, making it easy to replicate data from PostgreSQL to ClickHouse in real-time. By bringing together different data sources seamlessly, Dozer lets logistics companies create real-time data views using standard SQL and turn them into accessible APIs with minimal effort.
Dozer acts as a real-time analytics layer, ensuring that insights are obtained quickly and enabling confident decision-making based on data. Its scalability means that companies can focus on innovation without worrying about managing infrastructure, as Dozer can handle increasing data needs effortlessly.
In summary, by adopting this two-database strategy, logistics companies can make the most of their data, improving efficiency, enhancing customer experience, and staying competitive in the fast-paced logistics industry.