
Large Language Models (LLMs) are a type of AI that is trained on a massive amount of text data. This allows LLMs to generate text, translate languages, write content and answer in an informative way. However, LLMs are not perfect. They often make mistakes and produce text that is not coherent or relevant to the topic at hand. LLMs can sometimes generate inaccurate or misleading information, even if it sounds plausible. This is because they learn from statistical patterns in the data, which may not always correspond to reality. This issue can be particularly problematic in applications where factual accuracy is crucial.
One particular challenge lies in the issue of hallucinations, where LLMs produce outputs that are factually inaccurate or misleading. This phenomenon, often stemming from outdated training data, can have significant implications for the reliability and trustworthiness of LLMs.
Issues with LLMs
Hallucinations Problem:
Hallucinations in LLMs occur when the model's predictions deviate from reality, generating text that is inconsistent with the input or the broader context. This can manifest in various forms, such as fabricating facts, expressing outdated opinions, or drawing erroneous conclusions from data. The underlying cause of these hallucinations can be traced back to the training data upon which LLMs are built.
LLMs are trained on massive amounts of text and code, encompassing a vast repository of human knowledge. However, this data is not without its biases and imperfections. It may reflect societal prejudices, contain outdated information, or simply lack the nuance and context required for accurate understanding. When LLMs are trained on such flawed data, they may inherit these biases and imperfections, leading to hallucinations in their outputs.
Out-of-Date Training Data:
The presence of outdated data in training sets further exacerbates the hallucination problem. As technology and society evolve, information becomes obsolete, and LLMs trained on such data may struggle to keep pace with the changing world. This can lead to the generation of factually incorrect information or outdated opinions, undermining the credibility of LLMs and limiting their usefulness in real-world applications.
Retrieval Augmented Generation (RAG) is a promising approach to address the issues of hallucination and out-of-date training data in large language models (LLMs). RAG combines the strengths of LLMs with those of retrieval-based systems to generate more accurate and reliable text.
How RAG Works
RAG works by first retrieving relevant passages from an external knowledge source, such as a search engine or a document database. These passages are then used to provide context and anchor the LLM's generation process. This helps to ensure that the generated text is consistent with the retrieved information and less likely to contain hallucinations.
Librarian and the Writer Analogy
Imagine a large language model (LLM) as a highly skilled writer, but with a limited knowledge base. While this writer can craft compelling narratives and compose insightful essays, they lack access to the vast expanse of information available in the world. That's where RAG comes in, acting as the writer's resourceful assistant.
RAG functions like a diligent librarian, scouring external data stores to gather relevant information tailored to the user's request. This context-rich information, whether it's real-time updates, user-specific details, or even factual data that hasn't made it into the LLM's training set, is then seamlessly integrated into the writer's prompt.
With this enhanced prompt, the LLM is empowered to produce even more informative and personalized responses, akin to a writer armed with a wealth of background research. RAG, in essence, bridges the gap between the LLM's knowledge and the vast sea of information, elevating its capabilities to new heights.
Comparing RAG with Fine-tuning LLMs
Fine-tuning takes a pre-trained LLM model and trains it more on a smaller dataset, which was not used before to improve performance with relevant task.
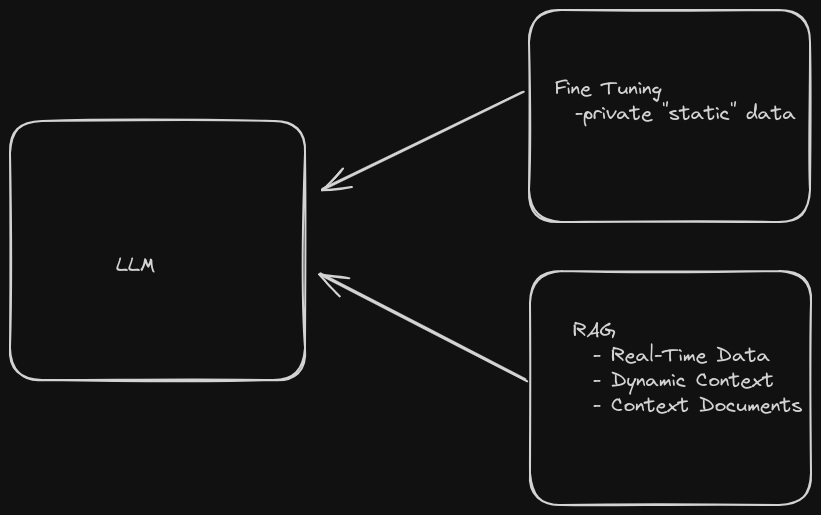
RAG is particularly well-suited for scenarios where you can enrich your LLM prompt with information that was not available during its training phase. This includes real-time data, personal or user-specific data, and contextual information relevant to the prompt. By incorporating such external knowledge, RAG enables LLMs to generate more accurate, relevant, and personalized responses.
Challenges with RAG
When working with data that is siloed or in real-time, implementing RAG can present significant challenges. Siloed data refers to information that is isolated or segregated within specific systems or databases, making it difficult to access and integrate with other data sources. Real-time data, on the other hand, is constantly changing and requires immediate processing to maintain relevance.
Siloed Data
Retrieval-Augmented Generation (RAG) relies on accessing and retrieving relevant information from external data sources to enhance the capabilities of large language models (LLMs). However, when the data is siloed or isolated within specific systems or databases, it becomes difficult for RAG to effectively utilize this information. This poses significant challenges for the implementation of RAG, as it hinders the LLM's ability to generate comprehensive and informative responses.
Real-time Data:
Real-time data, which is constantly changing and requires immediate processing to maintain relevance, presents another set of challenges for RAG. The LLM needs to be able to access and process real-time data streams with minimal latency to ensure that the generated text is always relevant and up-to-date. This can be challenging due to the high volume and dynamic nature of real-time data.
How Dozer can help with both the Challenges
Dozer is a powerful Data Access backend that simplifies the process of building and deploying data-driven applications. It provides a unified interface to access and process data from multiple sources, including databases, APIs, and streaming platforms. This enables developers to build applications that leverage real-time data without having to worry about the underlying infrastructure.
This means that you can use Dozer to ingest data from any source, such as a database in real-time, which allows you to mitigate the issues related to siloed data and real-time data.
Here are few ways Dozer helps with RAG
Real-time data ingestion: Dozer can be used to ingest real-time data from a variety of sources, such as social media feeds, customer interactions, and sensor data. This data can then be used to provide RAG models with the most up-to-date information.
Data transformation: Dozer's streaming SQL engine can be used to transform and process data in real time. This can be used to clean and prepare data for use by RAG models, as well as to extract features that are relevant to the task at hand.
Contextual information: Dozer can be used to store and manage contextual information, such as user profiles and knowledge graphs. This information can then be used to provide RAG models with a richer understanding of the context of the task at hand.
The resourceful assistant
So continuing the story of the writer and the librarian, Dozer is the resourceful assistant. Who steps into the scene, armed with its vast knowledge of data sources and its ability to seamlessly integrate external information. It acts as a bridge between the writer (LLM) and the vast library of information (external data sources), enabling the writer to access and utilize a broader range of knowledge.
Just as the librarian guides the writer to relevant books and articles, Dozer guides the LLM to the most pertinent data sources, providing it with the context and information needed to craft even more informative and personalized responses.
Dozer's role extends beyond mere retrieval; it also helps the writer process and transform the retrieved information, ensuring that it is in a format that can be readily incorporated into the text generation process. This collaboration between the writer, the librarian, and the assistant elevates the quality of the generated text, making it more comprehensive, accurate, and tailored to the user's needs.
With Dozer on board, the writer can confidently venture into unexplored territories of knowledge, knowing that its resourceful assistant will always be there to provide the necessary support and guidance. Together, they form an unstoppable team, capable of producing text that is not only informative but also insightful, engaging, and truly remarkable.
Conclusion
In conclusion, the combination of large language models (LLMs) and retrieval-augmented generation (RAG) has the potential to revolutionize the way we interact with computers. By providing LLMs with access to real-time data, personal data, and contextual information, RAG enables LLMs to generate more accurate, relevant, and personalized responses. Dozer is a data infrastructure platform that can be used to build and deploy RAG applications. It provides a number of features that can be helpful for RAG development, such as a streaming SQL engine for real-time data transformation, support for a variety of data sources, a distributed architecture that can scale to handle large data volumes, and a variety of security and compliance features.
The future of LLM-powered applications is bright, and RAG is playing a key role in this evolution. With Dozer, developers can easily build and deploy RAG applications that can take advantage of the latest advances in LLM technology.
In the upcoming articles, we will explore how to build RAG applications using Dozer and OpenAI's assistant. Stay tuned!
For more information and examples, check out the Dozer GitHub repository.
Stay tuned for more updates and exciting use cases of Dozer and OpenAI assistant.