
In the realm of language model-based (LLM) applications, leveraging the power of artificial intelligence and natural language processing has become increasingly prevalent. One such application is the creation of chatbots that conversationally interact with users. In this article, we explore how Dozer can significantly enhance the capabilities of LLM-based applications. Using a chatbot for a bank as our illustrative use case, we delve into the challenges faced in contextualizing the chatbot's knowledge and how Dozer can provide a solution by enriching the customer profile.

Requirements
To deliver a personalized and effective user experience, our LLM chatbot needs to possess knowledge in two key areas:
- Understanding the bank's products and services
- Having a comprehensive customer profile
Traditionally, the primary method of providing information to an LLM is through the use of context. However, there are inherent limitations to this approach, particularly concerning the limited space available for context. LLM models typically have constraints on context size, often limited to a few thousand tokens, although newer models like Anthropic have expanded this to support contexts of up to 100,000 tokens. Despite these advancements, incorporating extensive knowledge, such as comprehensive bank product information or detailed customer profiles, within the context remains challenging.
To overcome this limitation, a dynamic approach to context population is necessary. Rather than relying solely on a fixed context, the context can be dynamically populated based on the user prompt. This allows for the inclusion of specific and relevant information related to the user's query, enabling the LLM chatbot to provide more accurate and tailored responses. By dynamically adjusting the context, the chatbot can access the necessary knowledge and adapt its understanding to better address the user's needs.
A practical approach is to leverage text embeddings and a vector database. This approach involves the creation of a vector database that stores the text embeddings of the bank's product and service information. Text embeddings represent the semantic meaning of the text and can capture the relationships and similarities between different pieces of information.
In the context of our bank's chatbot, this approach can for example be applied when a user inquires about credit card products. Here's how it works:
- Vector database population: The bank's credit card information, including details such as card types, benefits, requirements, and features, is transformed into text embeddings. These embeddings capture the essential characteristics of the credit card descriptions and specifications, representing them as numerical vectors.
- User query processing: When a user interacts with the chatbot and asks a question about credit card options, the chatbot processes the query and extracts relevant keywords, such as "credit card," "options," or specific card types.
- Similarity search: The extracted keywords and contextual information are used to perform a similarity search within the vector database. The search aims to find the text embeddings that are most similar to the user's query, focusing on credit card-related information. By measuring the similarity between the user query and the stored text embeddings, the chatbot identifies the most relevant credit card details.
- Context population: The retrieved credit card knowledge, aligned with the user's query, is dynamically populated into the chatbot's context. This means that the relevant credit card information becomes part of the context considered by the chatbot when generating responses.
By leveraging text embeddings and a vector database, our bank's chatbot can efficiently retrieve and utilize the most relevant credit card information based on the user's query.
But, there is a problem!
However, even with the integration of the vector database to enhance the LLM chatbot's knowledge of the bank's products and services, there is an essential missing component - the customer profile. The chatbot lacks knowledge about individual customers and their specific details, which is crucial for providing relevant and personalized responses. For instance, when discussing credit card eligibility criteria, factors such as the customer's annual income play a significant role. Without access to detailed customer information, the chatbot may struggle to provide accurate and contextually appropriate responses. To truly create personalized experiences, it is essential to incorporate the customer's profile, including their financial history, subscribed products, investments, and other relevant data, into the chatbot's context. This way, the chatbot can deliver tailored information and meet the specific needs of each customer, enhancing their overall experience.
This is where Dozer plays a vital role. With its data integration capabilities, Dozer can seamlessly gather and consolidate customer data from various sources, such as core banking systems, CRM platforms, and transaction databases. By connecting to these sources and capturing real-time data updates, Dozer ensures that the customer profile remains accurate and up to date.
By leveraging a comprehensive customer profile, the LLM chatbot can access the necessary information to tailor its responses to the specific customer. Whether the customer is inquiring about credit card options, loan eligibility, or account details, the chatbot can draw from the enriched customer profile to provide relevant and personalized answers.
Putting it all together
The diagram above represents the architecture of an intelligent chatbot system that leverages Dozer, a vector database for storing the bank's knowledge base, and an LLM app powered by langchain for conversational interactions with users. At the core of the architecture is Dozer, which aggregates customer data from multiple source systems, ensuring a comprehensive and up-to-date customer profile. The vector database serves as the repository for the bank's general knowledge, encompassing products, services, policies, and more. The LLM app, integrated with langchain, acts as the intelligent conversational interface, leveraging the enriched customer profile from Dozer and the knowledge base from the vector database. Together, these components enable the chatbot to deliver personalized and accurate responses, providing users with a seamless and engaging banking experience.
Let's give it a try with ChatGPT
To validate our assumptions, we have provided ChatGPT a list of credit card options and a comprehensive customer profile:
- EveryDay VISA Card:
Benefits: 5% cashback on grocery shopping, 8% cashback on Esso, Shell, Chevron, 0.3% cashback on all other expenses
Requirements: $30,000 minimum annual income
Annual fee: 35$
- LiveFresh VISA Card:
Benefits: Up to 5% cashback on Online & Visa contactless spend, Additional 5% Green Cashback on selected Eateries, Retailers and Transport Services, 0.3% Cashback on All Other Spend
Requirements: $30,000 minimum annual income
Annual fee: 35$
- Miles&More VISA Card:
Benefits: 10 miles per dollar on hotel transactions at Kaligo, 6 miles on flight, hotel and travel packages at Expedia, 3 miles on online flights & hotel transactions (capped at S$5,000 per month), 2 miles per $ on overseas spend, 1.2 miles per $ on local spend, Receive 10,000 bonus miles when you pay for your annual fee
Requirements: $30,000 minimum annual income
Annual fee: 215$ + free second card
- Vantage VISA Card:
Benefits: Earn 1.5 miles per $ in local spend, Eaern 2.2 miles per $ in foreign spend, Earn up to 6 miles per S$1 on Expedia bookings, Up to 19% off on fuel spending at Esso
Requirements: $60,000 minumum annual income
Annual fee: 215$
- Super VISA Card:
Benefits:10X Points (4 miles per $1) on online purchases, 3X Points (1.2 miles per $1) on overseas purchases, 1X Point (0.4 miles per $1) on other purchases
Requirements: $50,000 minimum annual income
Annual fee: 70$
First name: John
Last name: Smith
annual income: 55,000$
address: 33 Tampines Street 86, Singapore 528573
Phone: 7763 6678
Owned priducts:
- checking account - balance: $32,122
- debit card - outstanding balance: $1,100
last month spending pattern:
Local spend:
- fuel 3,122$
- groceries: $7,233
- travel: $12,122
- food & beverages: $1455
- transportation: $345
Foreign spend:
- accomodation: $3433
- food and beverages: $1344
We then asked ChatGPT to start acting like a virtual bank teller. We will not provide a full transcript of the conveconversation, but only few interesting parts.
In the conversation below, the chatbot has effectively utilized the customer's profile and annual income to recommend suitable financial products. It analyzed the user's annual income, which is $55,000, and made recommendations based on this information. Notably, the chatbot did not propose credit cards that required a higher annual income, such as the Vantage VISA Card which has an income requirement of $60,000.
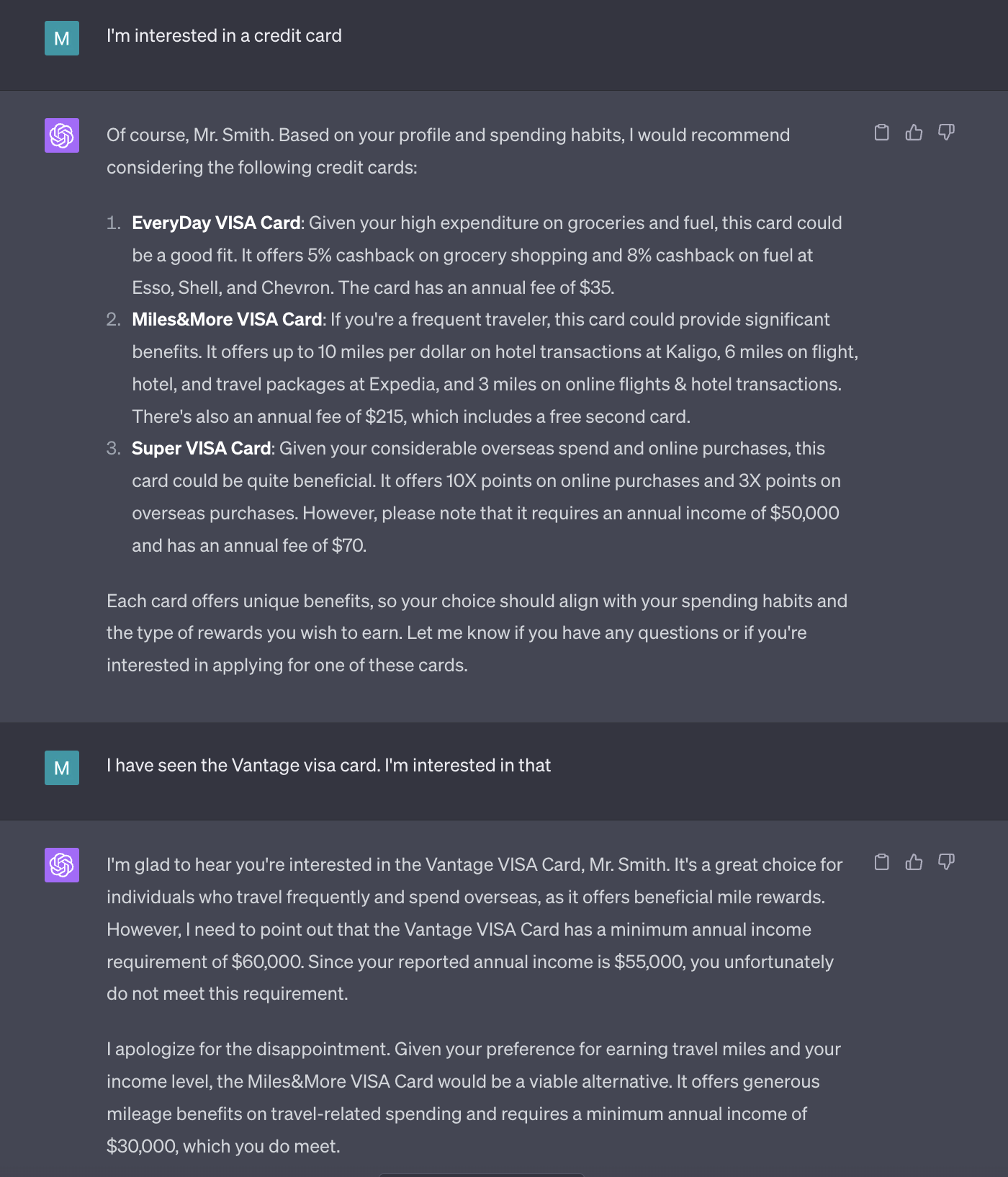
Also, when asked to estimate potential rewards, the chatbot used the customer's specific spending habits, applying different mile earning rates per spending category, to provide a personalized and detailed estimate of the possible miles to be earned with the Miles&More VISA Card.
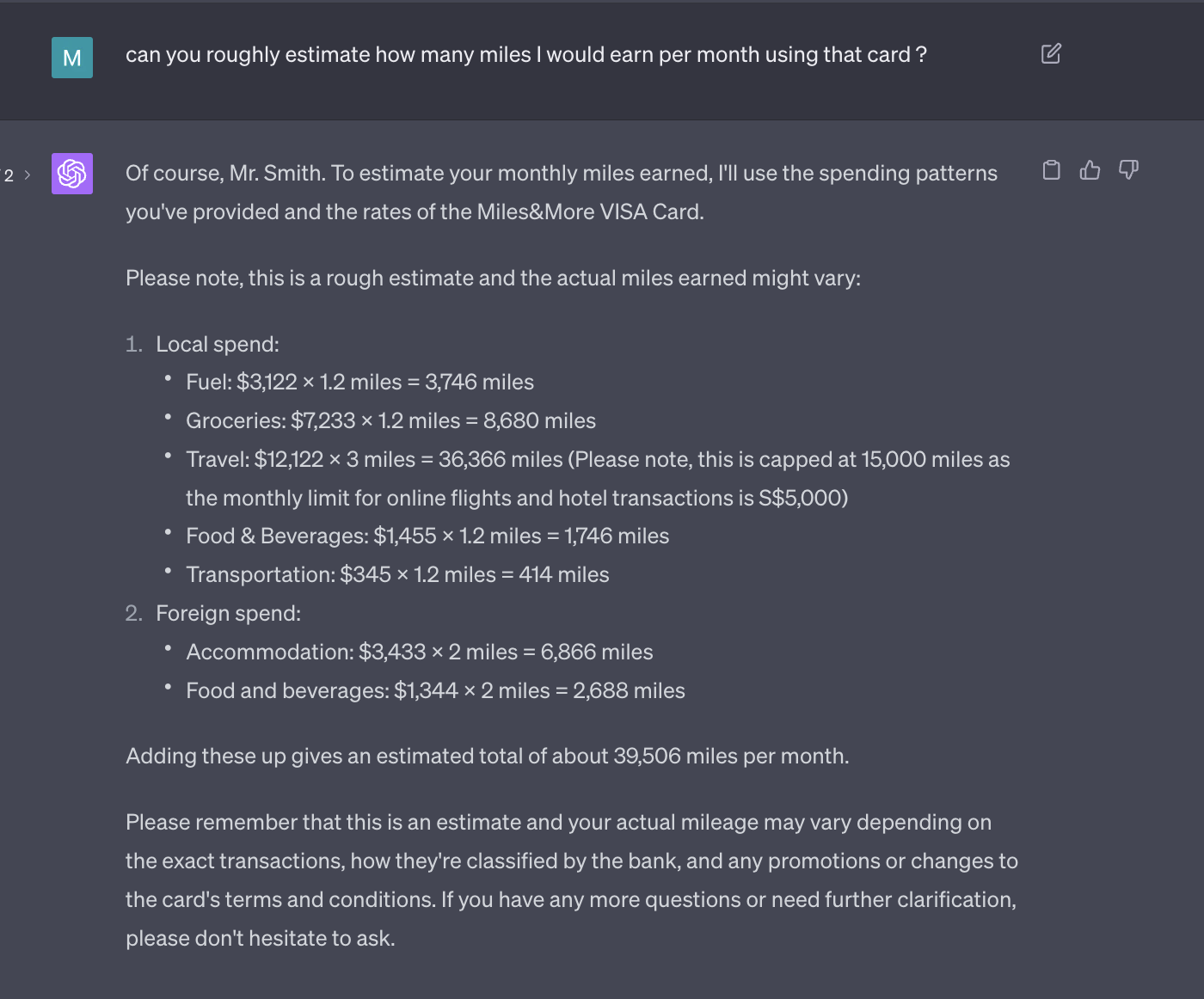
In the forthcoming post, we will provide a comprehensive example demonstrating how to implement such a system utilizing Langchain, Dozer, and a vector database.