
Ever come across occasions when you run into query performance issues for important queries that run on your database? This is when most companies will look to introducing a caching layer to improve the speed of queries.
In many scenarios you can probably fix your performance issues by introducing the right set of indexes. Or maybe denormalizing some fields to reduce the join overhead. These come with their own set of challenges such as having to write in two places etc and may even require code change. You might be working with a legacy platform where changing code is not straightforward.
What are your options in implementing a caching layer ?
Application Layer Cache using Redis/ Memcached / Dynamo Db etc Replicate data using CDC to an alternative DB/store optimised for your queries.
1) Application Layer Cache using Redis / Memcached / Dynamodb
This is a widely used approach where you would implement a caching layer by adapting one of these caching strategies.
- Cache Aside: Maintain data in both cache and primary DB
- Read Through: Typically implemented using a library / framework where it talks to the db if there is a cache miss
- Write Through: Write passes through
- Write Back: Write to cache first
Each of these strategies comes with its own set of pros and cons but the main differentiation is that application code has to deal with this complexity of caching logic.
2) Replicate data through CDC to a secondary database.
This approach has been gaining traction for read heavy operations. With tools such as Debezium and AWS Database Migration Service, companies are building pipelines that move data using a replication approach. The diagram below illustrates the typical components involved.
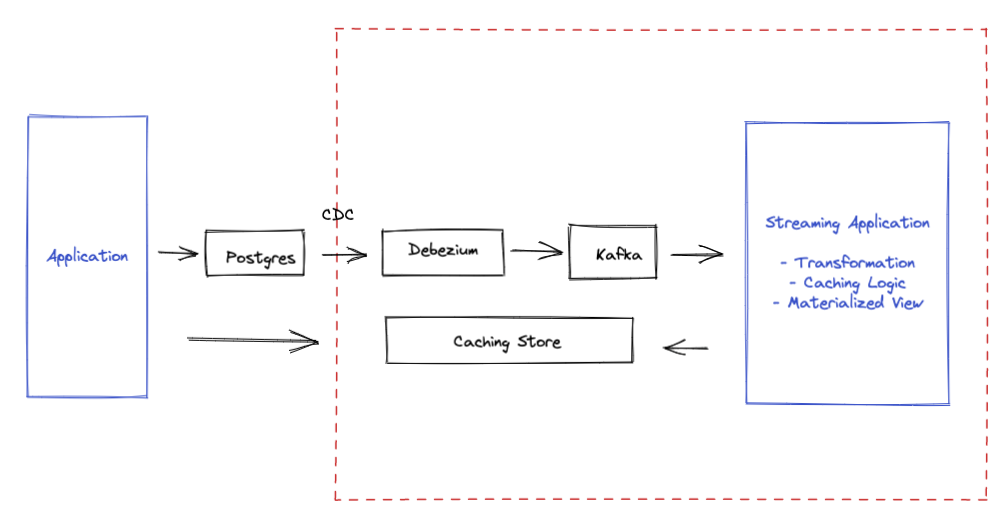
This can be implemented without modifying the original implementation. There are some considerations to take note of: Does data need to be real time? What types of indexes suit your querying needs? How do you guarantee availability? What happens if the schema in the primary database changes? What are the cost involved? This requires data engineering and skilled engineers to build and maintain.
In the next article (Part 2) we will be publishing a sample repository that demonstrates some of this in code. We are very excited at Dozer to build an end to end system that takes care of this exact problem statement. We are currently in the build phase and will publish our repository soon for developers to try. Please sign up on Dozer Website to get early access.