OpenAI has introduced a formidable competitor to Langchain agents, known as Assistants. These user-friendly, low-code tools, aim to offer an agent-like experience, enhanced retrievals, and improved function calling capabilities.
The Assistants API empowers you to construct AI assistants seamlessly integrated into your applications. These assistants, equipped with instructions, harness models, tools, and knowledge to adeptly address user queries. Presently, the Assistants API accommodates three essential tools: Code Interpreter, Retrieval, and Function Calling. The integration process for the Assistants API follows a straightforward flow:
Assistant Creation: Initiate an Assistant in the API, defining custom instructions and selecting a model. Optionally, enable tools like Code Interpreter, Retrieval, and Function Calling to enhance functionality.Thread Creation: Establish a Thread when a user initiates a conversation.Message Addition: Populate the Thread with Messages as users pose questions or interact.Assistant Execution: Invoke the Assistant on the Thread to elicit responses. This automatically engages the relevant tools, ensuring a dynamic and responsive interaction.
In this instance, we are embarking on the development of an assistant specialized in knowledge retrieval, specifically to answer questions about the rules of chess using a document. Once developed, we plan to test it in the Assistant Playground and potentially publish it to the GPT Store.
Setting Up the Client
The script kicks off with the straightforward import of the OpenAI package and the client's definition. It is recommended to handle the API key through an environment variable to prevent inadvertent leaks to version control systems.
from openai import OpenAI
import time
# Initialize Client
client = OpenAI(
api_key= "YOUR_API_KEY",
)
Uploading Knowledge Source
Following the client's initialization, the script proceeds to provide the knowledge source by uploading a file to the client's context.
# Upload file
file = client.files.create(
file=open("LawsOfChess.pdf", "rb"),
purpose='assistants'
)
Initializing the Chess Assistant
Once the file is uploaded and the client is set up, the next step is to select the model on which the assistant will run. The assistant is then initialized with the required tools and knowledge base. In this case, the assistant is named "Chess Assistant," and specific instructions are provided.
# Add the file to the assistant
assistant = client.beta.assistants.create(
name="Chess Assistant",
instructions="""You are an assistant to help people with the game of Chess. You know the rules. Use the knowledge found in the uploaded file to best respond to players' queries.""",
model="gpt-4-1106-preview",
tools=[{"type": "retrieval"}],
file_ids=[file.id]
)
Note the use of the "retrieval" tool, indicating the need to retrieve knowledge from external sources. OpenAI also supports tools like function calling and a code interpreter for more complex use cases.
Organizing Conversations with Threads
The script organizes conversations as "threads," similar to the "Chain Of Thought" concept for agents in Langchain .
# Create a thread
thread = client.beta.threads.create()
Interacting with the Chess Assistant
With the setup complete, the script proceeds to interact with the assistant by sending a message and waiting for a response.
# Send a message to the assistant
message = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content="What is Quickplay finish in Chess?",
file_ids=[file.id]
)
Running the Chess Assistant
The assistant is then run by associating the thread and assistant.
# Run the assistant
run = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id,
)
To complete the process, the script continually checks the status of the run until it is 'completed' and then processes the response.
# Wait for completion
while run.status != "completed":
time.sleep(1)
# Retrieve and print the answer
messages = client.beta.threads.messages.list(
thread_id=thread.id
)
print(f"ANSWER: {messages}")
Exploring Assistant Capabilities in OpenAI Playground
As we have seen, it is incredibly easy to setup an Assistant and use it for interaction. We can even view our assistant in the OpenAI Playground and test it online.
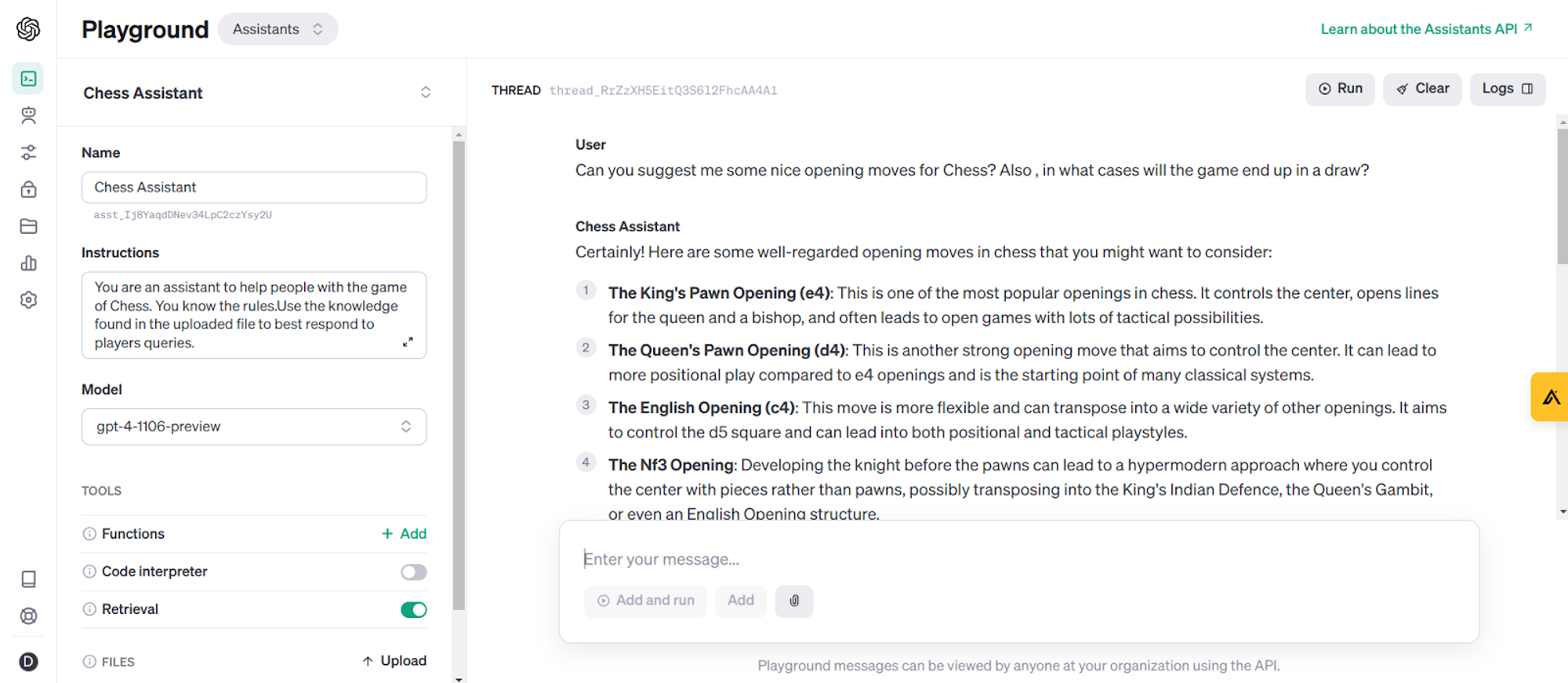
As we explore the capabilities of OpenAI's Assistant API, it's crucial to understand two key approaches to enhance the performance and relevance of your AI assistant: fine-tuning and retrieval.
Fine-tuning:
Fine-tuning involves training a pre-existing model on a specific dataset to tailor it for a particular task or domain. This is done to prevent the models to make a certain kind of mistake again and again. While fine-tuning allows for a high level of customization, it requires a considerable amount of domain-specific data and expertise. This process is ideal when your AI assistant needs to address very niche or specialized queries.
In the context of our chess assistant, fine-tuning could be applied to make the model more adept at answering intricate chess strategy questions or providing insights into specific chess openings. However, the trade-off is the resource-intensive nature of fine-tuning, both in terms of time and data.
Retrieval:
On the other hand, retrieval is a more flexible approach that leverages external knowledge bases or documents to enhance the assistant's responses. OpenAI's Assistant API supports the retrieval tool, allowing the assistant to pull in information from an external source.
In our chess assistant example, retrieval could be used to fetch the latest tournament results, rule updates, or any dynamic information related to chess. This ensures that the assistant stays up-to-date without the need for continuous fine-tuning.
Choosing the Right Approach:
The choice between fine-tuning and retrieval depends on the specific requirements of your AI application. If your domain is highly specialized and you have access to a substantial amount of domain-specific data, fine-tuning may be the preferred route. On the other hand, if your application requires constant updates or draws upon a diverse range of information, retrieval offers a more dynamic and resource-efficient solution.
In the pursuit of creating powerful GenAI applications, integrating real-time data is paramount. While static knowledge serves as the foundation, real-time data adds the fuel needed to power dynamic and hyper-personalized user experiences.
As showcased in the earlier sections, OpenAI's Assistant API, coupled with tools like retrieval, enables seamless integration of external knowledge sources. However, to truly unlock the potential of your chatbot, incorporating real-time data is essential. This could include the latest chess tournament results, rule updates, or even personalized user information. By integrating personalized user data, the assistant can tailor responses based on the user's preferences, history, or interactions, creating a more personalized and user-centric interaction.
Dozer, a powerful tool in the data integration landscape, allows you to effortlessly integrate real-time data from various sources, adding an additional layer of personalization and specificity to your assistant's responses.
As we continue our exploration, it's essential to highlight the versatility of these chatbots beyond the OpenAI Playground. We'll guide you through the steps to effortlessly integrate your assistant into third-party applications such as Slack, Microsoft Teams, and more.
Stay tuned for the upcoming articles, where we'll delve into the process of extending the reach of your assistant and unlocking its potential in various digital channels.
In the next segment, we'll specifically focus on the step-by-step process of integrating your assistant with popular messaging platforms using Dozer, enabling you to deploy your chatbot where your users are most active.
The era of AI-powered, data-integrated chatbots is here, and the possibilities are limitless. Join us as we continue to simplify, enhance, and redefine the landscape of interactive AI applications.